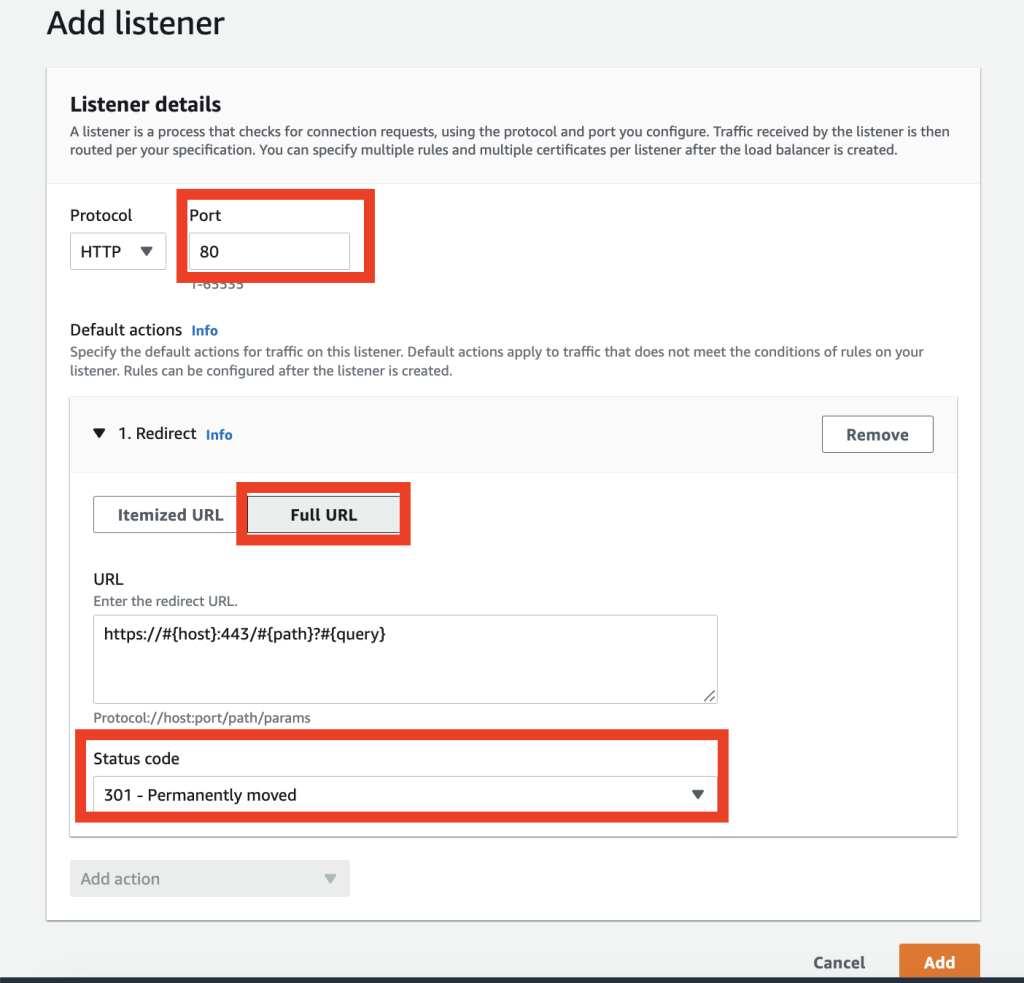
標題にある通り、LaravelからDynamoDBのデータを取得します。
その際に、AWSサービスの「Lambda」と「API Gateway」経由して取得します。
今回、かなり参考にさせて頂いた記事がこちらです。
AWS API GatewayとLambdaでDynamoDB操作
API Gateway → Lambda → DynamoDB までの部分はこちらを参考にさせて頂きつつ、
・途中でエラーで詰まった部分の紹介
・API GatewayとLaravelとの連携部分についての紹介(curlを利用します。)
をしていきます。
■前提
・Laravelインストール済み ・AWSアカウント取得済み
LaravelからDynamoDBのデータ取得の流れ
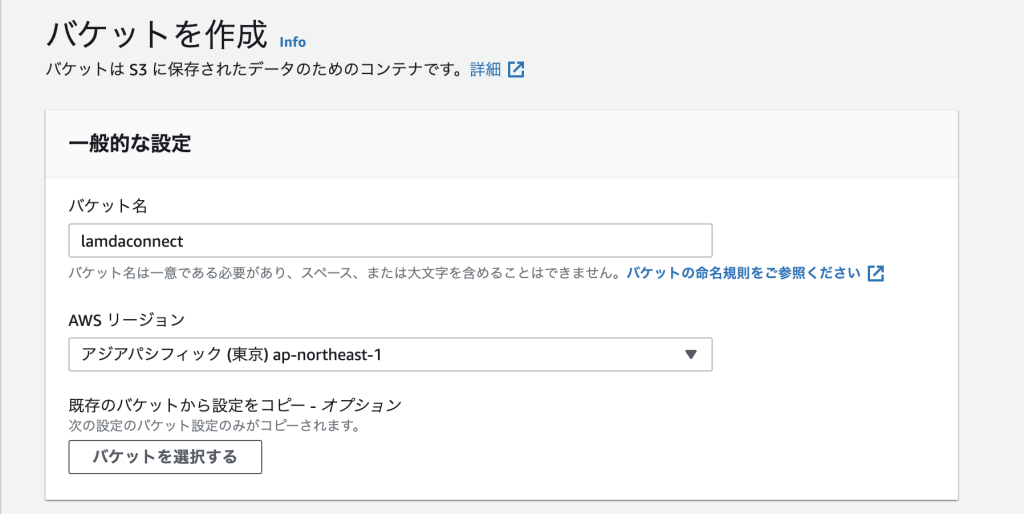
①:DynamoDBのテーブル、レコード作成
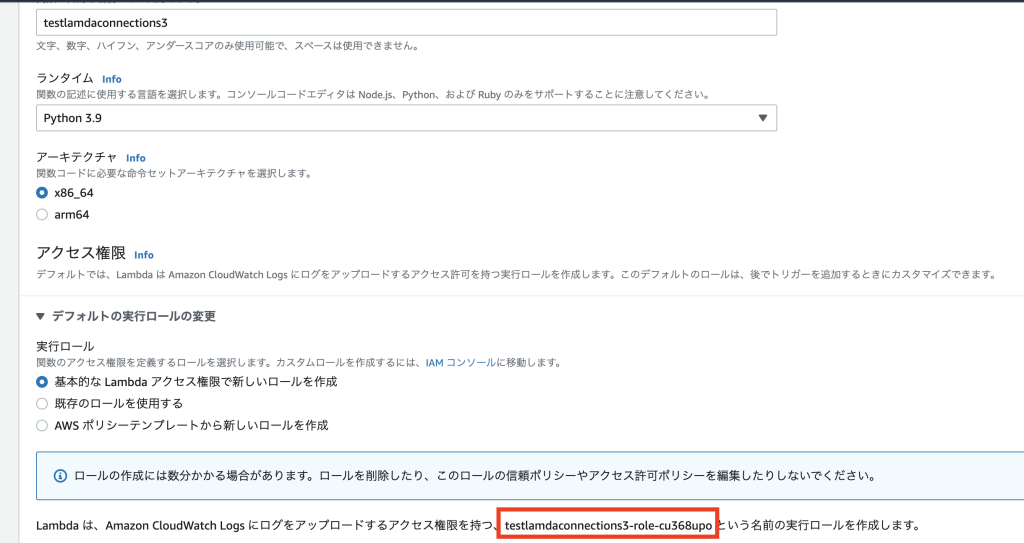
②:Lambda作成
③:API Gateway作成
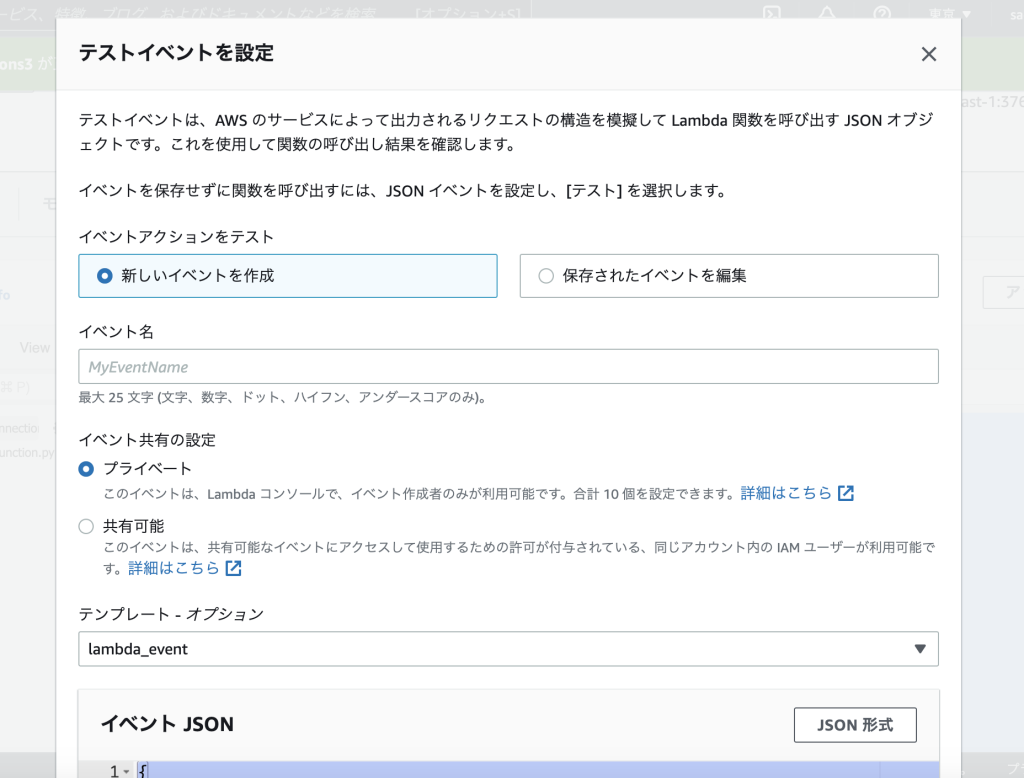
④:API Gatewayテスト実施
⑤:API Gateway公開
⑥:ローカル環境(mac / ターミナル)から、API Gatewayへリクエスト
⑦:LaravelからAPI Gatewayへリクエスト
おまけ:LaravelからAPI Gatewayの通信に認証を追加
①〜⑤は、こちらの記事を参考に進めて頂けたらと想います。 AWS API GatewayとLambdaでDynamoDB操作
⑥:ローカル環境(mac / ターミナル)から、API Gatewayへリクエスト
①~⑤で、API Gatewayテストが完了し、DynamoDBのデータが正しくResponseされているでしょうか。
■SCANを実施したい場合のコマンド
$ curl -X POST 'https://XXXXXX.execute-api.ap-northeast-1.amazonaws.com/APItest/dynamodbctrl' -d '{"OperationType":"SCAN"}' | jqここで自分が見誤った部分が、リクエストする際のURL部分です。
ステージエディターのURLを利用すれば問題ないのですが、階層によってURLが違うので注意して下さい。
こちらの方と同じ勘違いをして、「Missing Authentication Token」となってしまいました。 【AWS】APIGatewayのURLにアクセスするとエラー「Missing Authentication Token」が表示される
⑦:LaravelからAPI Gatewayへリクエスト
ローカル環境から、curlを利用してデータが返ってきましたか。
curlを利用して、LaravelからAPI Gatewayへリクエストして、DynamoDBのデータを取得していきます。
public function index()
{
$header = [
'Content-Type: application/json',
];
$params = [
"OperationType" => "SCAN"
];
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, env('AWS_APIGATEWAY_URL'));
curl_setopt($curl, CURLOPT_POST, TRUE);
curl_setopt($curl, CURLOPT_POSTFIELDS, json_encode($params));
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
$output= curl_exec($curl);
$result = json_decode($output);
curl_close($curl);
dd($result);
}
curlはPHPに標準で含まれているので、importをする必要はありません。
env(‘AWS_APIGATEWAY_URL’)
ステージの呼び出しURLを指定して下さい。

curl_setopt($curl,CURLOPT_POSTFIELDS, json_encode($params));
連想配列から、jsonへ変換しています。
これで、dd($result);で、ターミナルからcurlしたデータと同じデータが返ってくると思います。
LaravelからAPI Gatewayの通信に認証を追加
下記にてまとめております。